While reading one of my posts on survey construction, a friend of mine, Sarah, texted me and asked if I was going to discuss the use of artificial intelligence (AI)1 in writing survey questions. To be honest, I had not considered using AI to write a survey. In fact, I hadn’t really considered AI as an assistant or impediment to PX at all. But she reminded me that many see AI as a shiny new tool and are looking for ways to shorten their grunt-work time any way they can. So, while a survey designer has no need for an AI-generated survey, my whole essay series assumes people who are NOT trained survey designers making surveys and they might see it as a useful shortcut. The more I thought about it, the more I realized that AI is already entrenched in aspects of PX and I should address its values and its limitations since it will likely gain traction because it can do some things far faster and better than a human can. Of course, it can make things much worse faster and more completely than a human can as well but let us focus on what promise AI has in furthering the patient experience.
Before heading down this path, though, I think it is imperative to discuss what AI is, at least what it is as it relates to this essay. It is amazing how quickly we transitioned from AI as a rarefied expensive tool that was poorly-understood to being a buzzword used by marketing to sell any advanced feature on existing software. For this conversation, I will define AI as a computer science focused on solving questions or problems with a combination of brute force and complex reasoning based upon an ability to learn from past questions and problems. When I say, ‘brute force,’ I mean the ability to perform literally 100’s of billions of calculations a second. (And by ‘literally,’ I mean literally and not how some people use it, as figuratively.) In the PX sphere, the aspect of AI used most frequently is based upon some form of Natural Language Processing, or NLP. This is the ability to ‘read’ alphanumeric things and create counts and summaries of similar responses.
Right now, the place where AI is most frequently seen is in its ability to summarize verbatim or open field text. Comments left by patients, in my opinion, are poorly and inefficiently used.2 This was the subject of two other essays here, but for the moment, they are not reviewed consistently. When they are reviewed, it is usually with an eye towards powerful comments, good and bad, that can be read at a huddle or team meeting. It is difficult, even if you are looking for it, to find broad patterns across the days, weeks, or months3 of comments. Over a decade ago, vendors started offering their version of sentiment analysis that would read the broad tone of a comment and then bucket comments as positive, neutral, or negative. While this tool would struggle at times with modifying words—calling ‘awfully good’ or ‘terribly efficient’ as negative—it was a boon to being able to sift through the pile of comments looking for useful nuggets to share.
Since then, most vendors have added a more nuanced analysis of comments, generally using some form of Natural Language Processing. This takes the analysis one step further, by being able to pull multiple elements out of one comment and summarizing comments under broad topics, such as doctors’ ability to explain things, or attitudes about scheduling. One vendor, NRCHealth, allows clients to ask specific questions of subsets of verbatim comments. So, one could ask a question “What do patients say about parking at Clinic X?” and it will summarize those comments across any time range.4
There is one major limiting factor for these programs to work effectively and that is the volume of the source material. You can be confident in patterns observed from thousands of comments. You can be slightly less confident about patterns observed in fewer than one hundred comments. As you parse your data down, it is easy to lose sight of the number of comments being sifted through to generate those summaries. Especially since not all respondents leave useful comments. You may feel confident in the summary because you have fifty cases in your subset. But if only 40% leave useful comments, you are basing your summary on what twenty people said.
I once was tasked with summarizing thousands of verbatim comments. Given the nature of the data, it involved sorting through the entries with no responses and those which had some version of N/A or Not Applicable or Not Asked. I then read the remaining comments, trolling for common themes. This would take the better part of a day every quarter to perform. Once AI platforms appeared online, I could simply copy/paste the comments into the AI maw and let it summarize the comments. I would then review the summaries provided and go back to the source material to pull out prime examples of the summarized comments. This reduced my work to about an hour every quarter. It was a great time-saver. What I noticed, though, as I read the comments was that the importance of a topic was usually based upon its appearance relative to other topics. This may seem obvious, but this generated relative importance and not absolute importance. Given the nature of the text, once you filtered out all the chaff, the AI tool would proclaim that the most important topic was X, even though upon review, X only appeared in about four or five of the comments. This was certainly more than any other theme or topic, but it was hardly earthshattering, given that it appeared in about 1% of the total comments, and perhaps, 2-3% of the non-null comment fields. So, it was most important in the same sense that in the kingdom of the blind, the one-eyed person will rule.
Had I simply reported the AI findings, unchecked, I would have been overselling the results. The problem is that many will simply take what AI says at face value. Without verifying, they won’t know if Topic X is really a major issue or simply the most noticeable bump in a sea of white noise.
Now, I am sure that those proficient with AI tools will point out that one can change the settings or thresholds on what the NLP will use to set importance. I am sure that if I toyed around with it, I might have been able to generate a more useful first-draft. On the other hand, I am not an expert in working with AI and I suspect most people using it are in the same camp. They don’t want an advanced course of the vagaries of AI. They simply want to summarize meeting minutes, or PFAC notes, or survey comments without it taking their entire day.
But what about Sarah’s suggestion that one use AI to generate a set of survey questions? I went to Gemini5 and asked it to generate a clinic survey. I then had it narrow the survey down to specifically an outpatient lab encounter. Since I spent about twenty-seven seconds on this, it would not be fair for me to nit-pick the resulting survey. I would hope that people using it would use it as a first draft and not a finished product. There are a few things, though, that I will call out. Of course, these are things you might pick up yourself if you read my essays on survey construction.
The AI Introductions
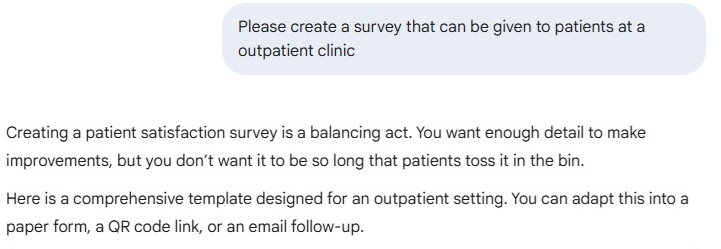

I like that it calls out the tension I discussed about balancing the line between generating useful data and keeping the process as brief as possible. It later says that a survey that has more than three questions will be discarded by the respondent. I would argue what, as you already know. I also like how, for the lab survey, Gemini shows why it selected the question topics that it did. That transparency is helpful.
The Demos


This is the thing many people forget. They don’t realize that this is likely the only way that they will know where the patient was or when the patient was there. The second set are the demos for outpatient lab, so asking if the encounter was scheduled or not is a very important and valuable piece of information. So, good catch, AI! Of course, if you are surveying for multiple lab sites, a question that asks for the location where the service was received would also be a necessity.
Clinic Questions
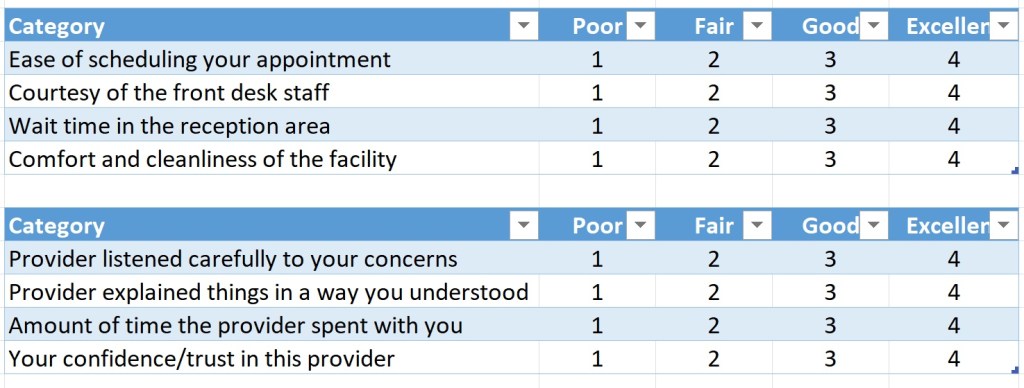
They used the format I suggested as well, where multiple elements are rated against a standing scale, turning eight questions into two questions. This is how Gemini can say that you should have no more than three questions while still getting more than three questions in the survey. I would disagree with the response categories, as I think that there is sufficient space between GOOD and EXCELLENT to declare the scale as incomplete. This is easily fixed with a VERY GOOD or ABOVE AVERAGE inserted between.
Lab questions
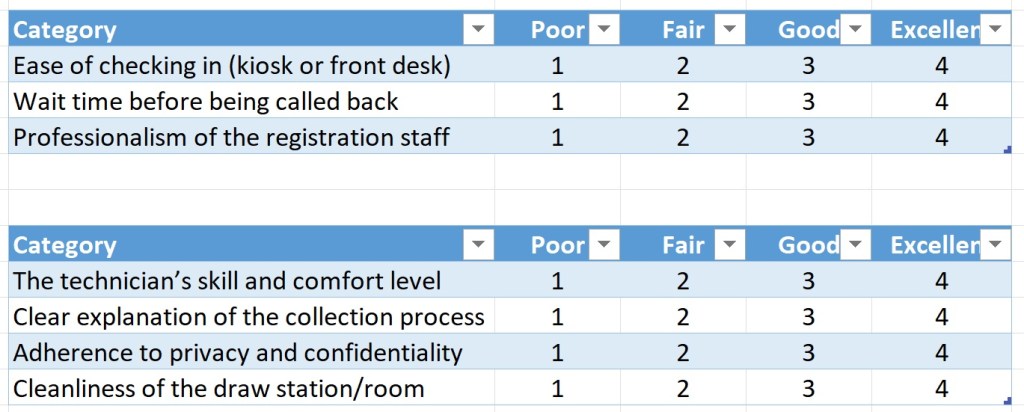
Here are the outpatient lab questions. I was pleasantly surprised that on its first pass, Gemini suggested important questions that I think are useful to ask. Only the lab question of “adherence to privacy and confidentiality” feels a bit unclear, especially from a patient’s perspective. I would wager that, when presented with the lab directors, they would say, “But how does a patient know this?”
Overall Rating Questions


The only other misstep is that, while they both have an Overall question, the questions differ in the survey. The clinic survey uses an 11-point Likelihood to Recommend question and the lab survey uses a 4-point Overall Satisfaction question. Neither are problems in themselves, but it does highlight the potential problem of having data that is not comparable over platforms. If we want to tear down silos and if we expect the primary care clinic and the outpatient lab department to have great synergy, then having a question that would allow you to compare scores between different surveys would be ideal. To be clear, this is less an issue with the AI survey and more an issue with the problems that can arise when multiple cooks in multiple kitchens work in isolation.
In the end, AI produced a very capable survey; one that requires tweaks more than overhauls. It still, though, is constructing a survey designed for the “average clinic” so your space may want to add some questions addressing a key issue you perceive exists. The only concern I have here is in the underlying architecture of the NLP, where a failure to understand the source data may lead to getting out over your skis.
1I generally spell out abbreviations before I use them. I am not sure AI needs that service for readers, but there you have it.
2I remember once when a doctor, having learned that I did not read the thousands of comments left every day, incredulously asked, “if you aren’t reading them, then who is?” To which I responded, “Well, given that you get your comments emailed to you every week, I assume it should be you.”
3Speaking of AI, I read somewhere that the use of the ‘oxford comma’ is evidence of AI having written something. I weep for the fact that proper grammar is evidence of superhuman intellect. Or maybe I should take that as I massive compliment.
4I would assume that other vendors have similar features, but I am not familiar enough with their current offerings to know. Anyone using another vendor is welcome to answer in the comments if their vendor offers some version of NLP.
5As with every company I reference, my use of Google’s AI engine should not be inferred as a recommendation.

Leave a comment